
如何理解深度学习领域中的端到端 (end to end)
如何理解深度学习领域中的端到端 (end to end)
前情提要
我已经有一年多没有更新自己的博客了,说来实在可惜,原本让我引以为傲的博客网站成为了久久不变的一堆代码,甚至让我自己都不再敢点了进来。这期间,不断有更新博客的想法,但几个问题一直困扰着我:
- 更新什么主题?这个问题还好回答,有太多我在学习或者我尚不知道需要去学习的知识理论,有太多我得到的感触和收获。这段时间,我经历了很多,无论是成绩还是挫折,我觉得只要我想,没有写不出来的。关键在于第二个问题:
- 更新什么内容?现在博客网站如 博客园、CSDN 、知乎乃至国外的博客网站很多,当我想写一点东西,或者想学一点东西的时候,我发现,博客上已经总结的很到位了,写的也很出色。计算机届有一句话,叫做 “不要去造重复的轮子”,我担心我所写的东西并没有创新的观点便不值得写。
如此以来,总是拖着,就久久没有更新。
那为何突然又想写了呢,而且是这个主题 如何理解深度学习领域中的端到端(end to end) ,我的思维历程还是比较丰富的:
不断学习,不断进步: 最近在北京参加实习,接触到了太多前沿的技术,大语言模型日新月异,几天之内就有新的成果产出,只有不断学习和记录,才能跟上前沿的步伐。
脚踏实地,虚心领会: 为了紧跟前沿步伐,在深度学习领域,我有太多一知半解的概念和理解不到位的点,然而我却常常不认为很重要,我觉得这并没有做到自己对自己最基本的要求:“虚心”。就比如这个概念,
端到端,其实我在很多论文、书籍、博客中看到了这个概念,但就是一晃而过,并没有太多的停留,我觉得这是不合适的,工科学习,需要有脚踏实地的态度,所以我专门写一篇对这个概念新的理解,以此打开我博客撰写的新方向。膜拜大神,不忘初心: 最近在研究 LLM 的外推技术的时候,不经意认识到了苏剑林,苏神,他提出了Transformer 中一种新的位置编码 Rope ,是中国人对大模型领域最大的贡献之一,在继续了解的过程中,闯入了苏神的博客科学空间,发现他从 16 岁,就开始搭建自己的博客网站,目前已经有几千篇原创精致博文涉及数学、天文、计算机、生活、科学等各个领域。让我实在膜拜。想来自己搭建博客网站的初心,不正是想成为像他这样的人吗?
image-20240313164715844 苏神博客网站“科学空间”首页
前情提要有点多,让我们直接进入这个概念的理解,端到端 !
什么是端到端
端到端的含义涉及到不同的领域,比如,在计算机科学和信息技术领域中,端到端的概念指的是一种通信方式,数据从发送方直接传输到接受方,而不需要中间环境对数据内容进行解析和处理,在通信领域内,端到端的模式强调的是数据传输过程中的直接性和完整性。
类似的,这个概念引申到深度学习和人工智能领域,端到端的概念表示 模型可以直接利用输入数据而不需要其他处理 。因此,我们可以看到,端到端或者非端到端,往往是形容一个模型对输入数据的要求。如果模型可以直接通过输入原始数据来得到输出,那么我们就说这个模型是端到端的,(可以理解为从输入端直接到输出端的)。
那与之相反的,传统机器学习方法,往往不能直接利用原始数据,而需要提前对原始数据进行一定的处理,比如降维、特征提取等方法,那么这种方法就不能称之为端到端的学习方法。
例如,我们可以用下面的两张图直观表示端到端和非端到端:
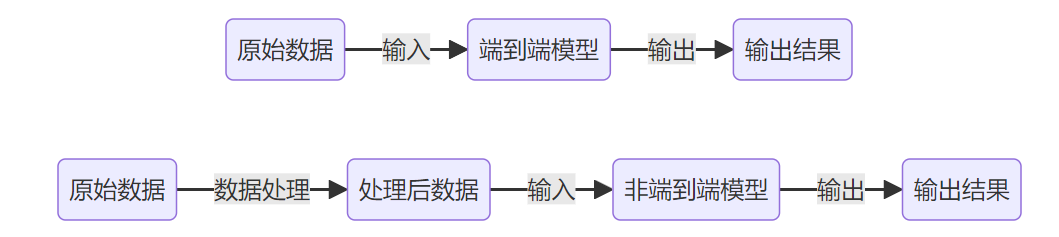
端到端模型直接将原始数据作为输出返回输出结果,非端到端模型需要使用经过数据处理后的处理数据作为模型输入
这两张图都是用 markdown 的 mermaid 画的,简单方便,以防止某些博客网站不支持 markdown 的这个语法,以图形方式呈现:
非端到端模型与端到端模型示例
为了更好的理解这两种模型,我们需要举个例子,在举例之前,我首先想先介绍下,有哪些数据处理的方法,也就是对于非端到端模型需要去做的而端到端模型不需要做的步骤,在这个基础上,可能更好的理解这个概念:
数据处理是机器学习和数据分析中的一个关键步骤,尤其是在非端到端模型中,这些步骤对于提高模型性能至关重要。以下是一些常见的数据处理方法,这些方法在非端到端模型中尤为重要,而在端到端模型中可能不那么必要或完全不需要:
- 特征工程:包括特征选择、特征提取和特征构造。这些步骤旨在从原始数据中识别、选择和转换出对模型预测最有用的信息。
- 数据清洗:移除或填补缺失值、修正错误或不一致的数据、处理异常值等,以确保数据的质量和准确性。
- 数据转换:将非数值型数据转换为数值型数据(如通过独热编码或标签编码),或者将连续数据离散化。
- 归一化/标准化:调整数据的尺度,使其落在特定的范围内(如[0, 1]或均值为0,标准差为1),以便于模型更好地学习。
- 降维:通过PCA、LDA等方法减少数据的维度,以减少计算复杂度和避免过拟合。
- 去相关:减少特征之间的相关性,避免多重共线性问题,提高模型的稳定性。
- 数据平衡:在处理不平衡数据集时,通过过采样少数类别或欠采样多数类别来平衡各类别的样本数量。
在端到端模型中,如深度学习网络(例如CNN、RNN等),很多这些预处理步骤可以被简化或完全省略,因为这些模型能够自动从原始数据中学习到有用的特征表示。端到端模型的设计目标是直接从输入数据到输出结果,减少人为干预和预处理的需求。然而,即使在端到端模型中,适当的数据预处理仍然可能有助于提高模型的性能和训练效率。
典型的端到端模型 —— CNN
CNN,卷积神经网络,算是我进入深度学习领域接触到的第一个应用级别的神经网络,他以及众多神经网络模型的端到端体现在于可以直接向模型输入原始图像,而不需要如提取特征这样的处理,根本原因在于,CNN 一连串的隐藏层在不断训练和学习的过程中,已经学会了自动识别输入图像的特征,这也是深度学习神经网络里最强大的能力之一,就是抽象输入原始数据特征。

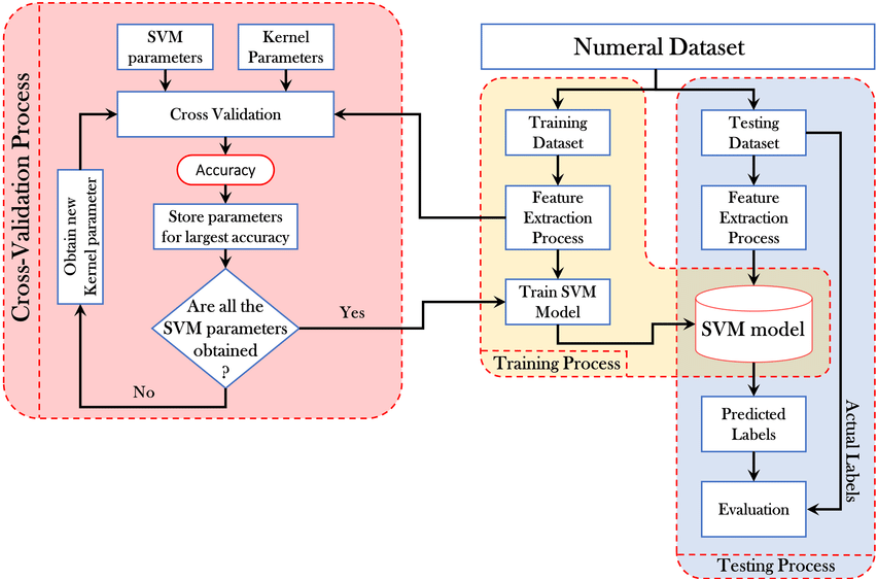
典型的非端到端模型——SVM
支持向量机(SVM)是一种监督学习方法,主要用于分类和回归任务。SVM 的过程主要包括数据预处理、选择核函数、训练 SVM 模型、模型评估等方面。SVM使用核技巧来将数据映射到高维特征空间,以便能够找到一个超平面来分隔数据。选择合适的核函数(如线性核、多项式核、径向基函数(RBF)核等)是很重要的。而核函数的主要功能就是将原始数据转换为一个新的空间,使得数据的分布变得更加线性可分,从而简化 SVM 的优化问题。因此,SVM 不能直接用原始数据,需要数据处理过程,因此,他不是端到端的模型。
其余案例:
- Nvidia的基于CNNs的end-end自动驾驶,输入图片,直接输出steering angle。从视频来看效果拔群,但其实这个系统目前只能做简单的follow lane,与真正的自动驾驶差距较大。亮点是证实了end-end在自动驾驶领域的可行性,并且对于数据集进行了augmentation。链接:https://devblogs.nvidia.com/parallelforall/deep-learning-self-driving-cars/
- Google的paper: Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection,也可以算是end-end学习:输入图片,输出控制机械手移动的指令来抓取物品。这篇论文很赞,推荐:https://arxiv.org/pdf/1603.02199v4.pdf
- DeepMind神作Human-level control through deep reinforcement learning,其实也可以归为end-end,深度增强学习开山之作,值得学习:http://www.nature.com/nature/journal/v518/n7540/full/nature14236.html
- Princeton大学有个Deep Driving项目,介于end-end和传统的model based的自动驾驶之间,输入为图片,输出一些有用的affordance(实在不知道这词怎么翻译合适…)例如车身姿态、与前车距离、距路边距离等,然后利用这些数据通过公式计算所需的具体驾驶指令如加速、刹车、转向等。链接:http://deepdriving.cs.princeton.edu/
参考:https://geek.csdn.net/65d6b0b3b8e5f01e1e4660c8.html
端到端学习的意义
端到端学习(End-to-End Learning)的意义在于它简化了机器学习模型的设计和训练过程,同时在许多情况下能够提高模型的性能和泛化能力。以下是端到端学习的几个关键意义:
- 简化流程:端到端学习模型直接从原始输入数据到最终输出进行学习,无需复杂的特征工程或预处理步骤。这大大简化了模型的开发流程,减少了人工干预的需求。
- 自动特征学习:端到端模型能够自动发现并学习数据中的关键特征,这些特征对于完成特定任务(如分类、回归、序列预测等)是至关重要的。这种自动特征学习的能力减少了对领域专家知识的依赖。
- 提高性能:在许多应用中,端到端学习模型已经证明能够达到或超过传统机器学习模型的性能。特别是在图像识别、自然语言处理和语音识别等领域,深度学习模型(一种端到端学习的方法)已经取得了突破性的成果。
- 泛化能力:端到端学习模型通常具有较好的泛化能力,因为它们能够从大量数据中学习到复杂的模式和结构,而不是依赖于有限的、人为设计的特征。
- 处理复杂数据:端到端学习模型特别适合处理高维和复杂的数据类型,如图像、视频和音频数据。这些模型能够捕捉到数据中的细微差别和深层次的关系。
- 可扩展性:端到端学习模型可以很好地扩展到大规模数据集和复杂任务,这在大数据时代尤为重要。